

In the previous sections, we examined the purposes for using different types of codes when humans and machines enter and store data. Next, we examine a few heuristics for establishing a coding system. These rules are highlighted in the list below.
The Eight General Guidelines for Establishing a Coding System
- Keep codes concise
- Keep codes stable
- Make codes that are unique
- Allow codes to be sortable
- Avoid confusing codes
- Keep codes uniform
- Allow for modification of codes
- Make codes meaningful
Codes should be concise. Overly long codes mean more keystrokes and consequently more errors. Long codes also mean that storing the information in a database will require more memory.
Short codes are easier for people to remember and easier to enter than long codes. If codes must be long, they should be broken up into subcodes. For example, 5678923453127 could be broken up with hyphens as follows: 5678-923-453-127. This approach is much more manageable and takes advantage of the way people are known to process information in short chunks. Sometimes codes are made longer than necessary for a reason. Credit card numbers are often long to prevent people from guessing a credit card number. Visa and MasterCard use 16-digit numbers, which would accommodate nine trillion customers. Because the numbers are not assigned sequentially, chances of guessing a credit card number are very slight.
Stability means that the identification code for a customer should not change each time new data are received. Earlier, we presented an alphabetic derivation code for a magazine subscription list. The expiration date was not part of the subscriber identification code because it was likely to change.
Don’t change the code abbreviations in a mnemonic system. Once you have chosen the code abbreviations, do not try to revise them, because that makes it extremely difficult for data entry personnel to adapt.
For codes to work, they must be unique. Make a note of all codes used in the system to ensure that you are not assigning the same code number or name to the same items. Code numbers and names are an essential part of the entries in data dictionaries, discussed in Chapter 8.
If you are going to manipulate the data usefully, the codes must be sortable. For example, if you were to perform a text search on the months of the year in ascending order, the “J” months would be out of order (January, July, and then June). Dictionaries are sorted in this way, one letter at a time from left to right. So, if you sorted MMMDDYYYY where the MMM stood for the abbreviation for the month, DD for the day, and YYYY for the year, the result would be in error.
Figure below shows what would happen if a text search were performed on different forms of the date. The third column shows a problem that was part of the year 2000 (Y2K) crisis that caused some alarm and even made the cover of Time magazine.
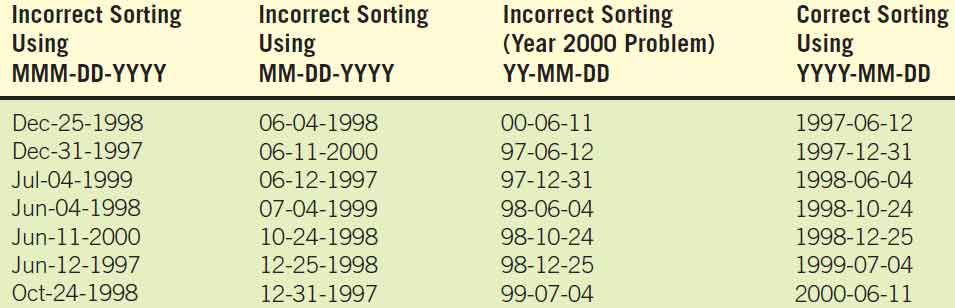
One of the lessons learned is to make sure that users can do what you intend them to do with the codes you create. Numeric codes are much easier to sort than alphanumerics; therefore, consider converting to numerics wherever practical.
Try to avoid using coding characters that look or sound alike. The characters O (the letter oh) and 0 (the number zero) are easily confused, as are the letter I and the number 1, and the letter Z and the number 2. Therefore, codes such as B1C and 280Z are unsatisfactory.
One example of a potentially confusing code is the Canadian Postal Code, as shown in the figure below. The code format is X9X 9X9, where X stands for a letter and 9 stands for a number. One advantage to using letters in the code is to allow more data in a six-digit code (there are 26 letters, but only 10 numbers). Because the code is used on a regular basis by Canadians, the code makes perfectly good sense to them. To foreigners sending mail to Canada, however, it may be difficult to tell if the second-to-last symbol is a Z or a 2.

To be effective and efficient for humans, codes need to follow readily perceived forms most of the time. Codes used together, such as BUF-234 and KU-3456, are poor because the first contains three letters and three numbers, whereas the second has only two letters followed by four numbers.
When you are required to add dates, try to avoid using the codes MMDDYYYY in one application, YYYYDDMM in a second, and MMDDYY in a third. It is important to keep codes uniform among as well as within programs.
Adaptability is a key feature of a good code. The analyst must keep in mind that the system will evolve over time, and the coding system should be able to encompass change. The number of customers should grow, customers will change names, and suppliers will modify the way they number their products. The analyst needs to be able to forecast the predictable changes that business users will desire and anticipate a wide range of future needs when designing codes.
Unless the analyst wants to hide information intentionally, codes should be meaningful. Effective codes not only contain information, but they also make sense to the people using them. Meaningful codes are easy to understand, work with, and recall. The job of data entry becomes more interesting when working with meaningful codes instead of just entering a series of meaningless numbers.
Codes are used in a number of ways. In validation programs, input data is checked against a list of codes to ensure that only valid codes have been entered. In report and inquiry programs, a code stored on a file is transformed into the meaning of the code. Reports and displays should not show or print the actual code. If they did, the user would have to memorize code meanings or look them up in a manual. Codes are used in GUI programs to create drop-down lists.