

Files
A file contains groups of records used to provide information for operations, planning, management, and decision making. The types of files used are discussed first, followed by a description of the many ways conventional files can be organized.
Files can be used for storing data for an indefinite period of time, or they can be used to store data temporarily for a specific purpose. Master files and table files are used to store data for a long period. The temporary files are usually called transaction files, work files, or report files. Master Files Master files contain records for a group of entities. The attributes may be updated often, but the records themselves are relatively permanent. These files tend to have large records containing all the information about a data entity. Each record usually contains a primary key and several secondary keys.
Although the analyst is free to arrange the data elements in a master file in any order, a standard arrangement is to place the primary key field first, followed by descriptive elements, and finally by elements that change frequently with business activities. Examples of a master file include patient records, customer records, a personnel file, and a parts inventory file.
Table Files A table file contains data used to calculate more data or performance measures. One example is a table of postage rates used to determine the shipping costs of a package. Another example is a tax table. Table files usually are read only by a program.
Transaction Files A transaction file is used to enter changes that update the master file and produce reports. Suppose a newspaper subscriber master file needs to be updated; the transaction file would contain the subscriber number, and a transaction code such as E for extending the subscription, C for canceling the subscription, or A for address change. Then only information relevant to the updating needs to be entered; that is, the length of renewal if E, and the address if A. No additional information would be needed if the subscription were canceled. The rest of the information already exists in the master file. Transaction files may contain several different types of records, such as the three used for updating the newspaper subscription master, with a code on the transaction file indicating the type of transaction.
Report Files When it is necessary to print a report when no printer is available (e.g., when the printer is busy printing other jobs), a report file is used. Sending the output to a file rather than a printer is called spooling. Later, when the device is ready, the document can be printed. Report files are very useful, because users can take files to other computer systems and output to specialty devices.
Relational Databases
Databases can be organized in several ways. The most common type of database is a relational database. A relational database is organized in meaningful tables, which minimizes the repetition of data, which in turn minimizes errors and storage space.
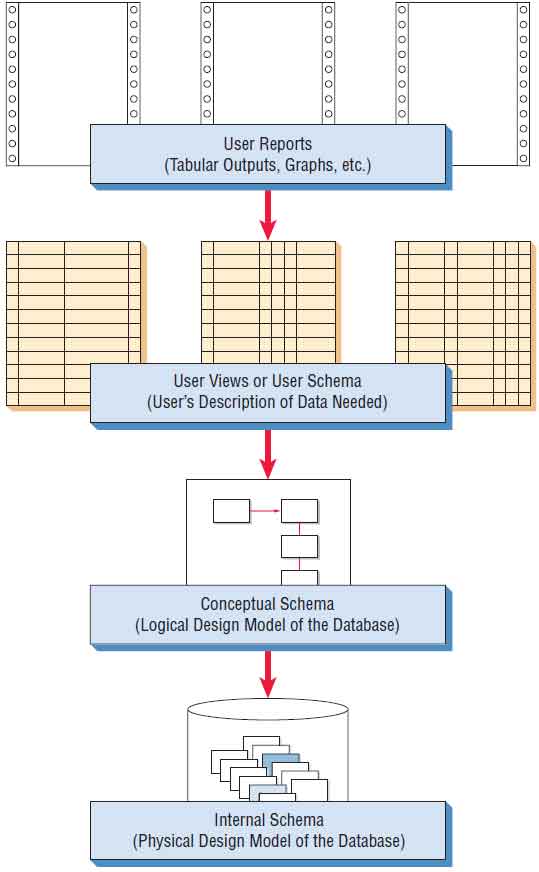
A database, unlike a file, is intended to be shared by many users. It is clear that the users all see the data in different ways. We refer to the way a user pictures and describes the data as a user view. The problem, however, is that different users have different user views. These views need to be examined by the systems analyst, and an overall logical model of the database developed. Finally, the logical model of the database must be transformed into a corresponding physical database design. Physical design is involved with how data are stored and related, as well as how they are accessed.
In database literature, the views are referred to as schema. Figure 13.8 shows how the user reports and user views (user schema) are related to the logical model (conceptual schema) and physical design (internal schema).
There are three main types of logically structured databases: hierarchical, network, and relational. The first two types may be found in legacy (older) systems. An analyst today would typically design a relational database.
A relational data structure consists of one or more two-dimensional tables, which are referred to as relations. The rows of the table represent the records, and the columns contain attributes.
Figure 13.9 shows the relational structure for a music CD ordering database. Here, three tables are needed to (1) describe the items and keep track of the current price of CDs (ITEM PRICE), (2) describe the details of the order (ORDER), and (3) identify the status of the order (ITEM STATUS).
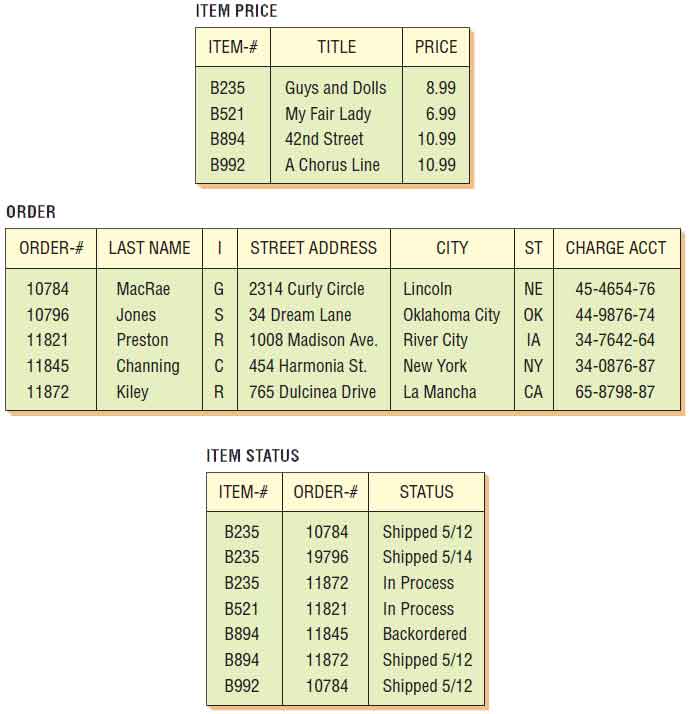
To determine the price of an item, we need to know the item number to be able to find it in the relation ITEM PRICE. To update G. MacRae’s credit card number, we can search the ORDER relation for MacRae and correct it only once, even though he ordered many CDs. To find out the status of part of an order, however, we must know the ITEM-# and ORDER-#, and then we must locate that information in the relation ITEM STATUS.
Maintaining the tables in a relational structure is usually quite simple when compared with maintaining a hierarchical or network structure. One of the primary advantages of relational structures is that ad hoc queries are handled efficiently.
When relational structures are discussed in database literature, different terminology is often used. A file is called either a table or relation, a record is usually referred to as a tuple, and the attribute value set is called a domain.
For relational structures to be useful and manageable, the relational tables must first be normalized. Normalization is detailed in the following section.