Data flow diagrams can and should be drawn systematically. Table illustrated below summarizes the steps involved in successfully completing data flow diagrams. First, the systems analyst needs to conceptualize data flows from a top-down perspective.
| Developing Data Flow Diagrams Using a Top-Down Approach |
|---|
|
To begin a data flow diagram, collapse the organization’s system narrative (or story) into a list with the four categories of external entity, data flow, process, and data store. This list in turn helps determine the boundaries of the system you will be describing. Once a basic list of data elements has been compiled, begin drawing a context diagram.
Here are a few basic rules to follow:
- The data flow diagram must have at least one process, and must not have any freestanding objects or objects connected to themselves.
- A process must receive at least one data flow coming into the process and create at least one data flow leaving from the process.
- A data store should be connected to at least one process.
- External entities should not be connected to each other. Although they communicate independently, that communication is not part of the system we design using DFDs.
Creating the Context Diagram
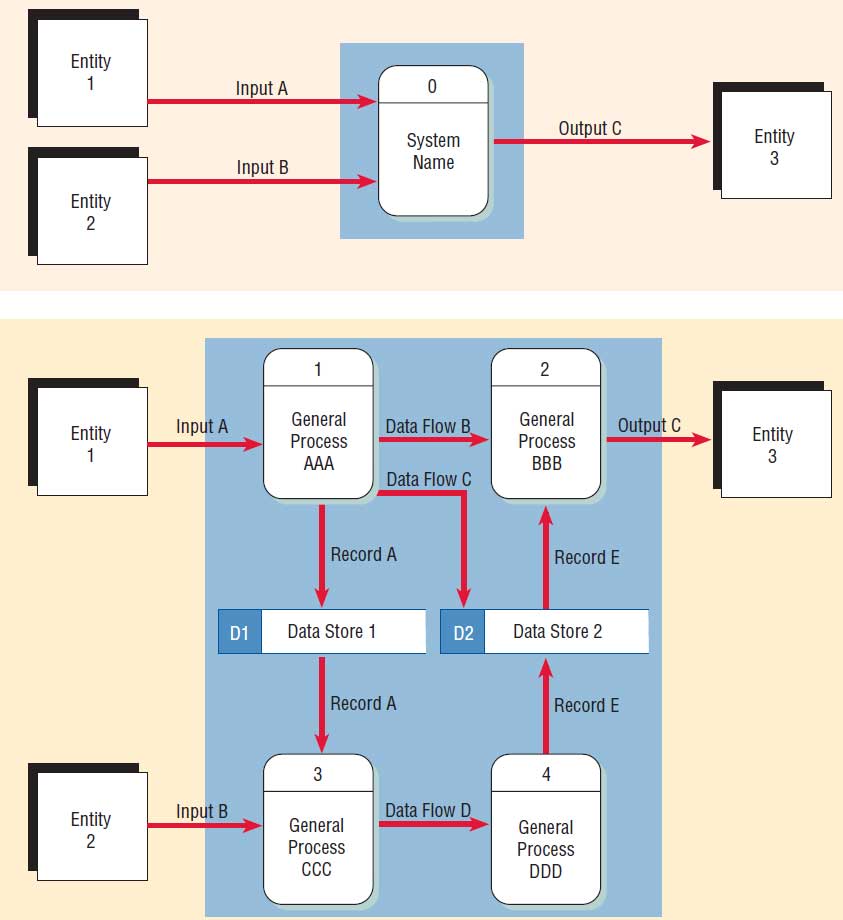
With a top-down approach to diagramming data movement, the diagrams move from general to specific. Although the first diagram helps the systems analyst grasp basic data movement, its general nature limits its usefulness. The initial context diagram should be an overview, one including basic inputs, the general system, and outputs. This diagram will be the most general one, really a bird’s-eye view of data movement in the system and the broadest possible conceptualization of the system.
The context diagram is the highest level in a data flow diagram and contains only one process, representing the entire system. The process is given the number zero. All external entities are shown on the context diagram, as well as major data flow to and from them. The diagram does not contain any data stores and is fairly simple to create, once the external entities and the data flow to and from them are known to analysts.
Drawing Diagram 0 (The Next Level)
More detail than the context diagram permits is achievable by “exploding the diagrams.” Inputs and outputs specified in the first diagram remain constant in all subsequent diagrams. The rest of the original diagram, however, is exploded into close-ups involving three to nine processes and showing data stores and new lower-level data flows. The effect is that of taking a magnifying glass to view the original data flow diagram. Each exploded diagram should use only a single sheet of paper. By exploding DFDs into subprocesses, the systems analyst begins to fill in the details about data movement. The handling of exceptions is ignored for the first two or three levels of data flow diagramming.
Diagram 0 is the explosion of the context diagram and may include up to nine processes. Including more processes at this level will result in a cluttered diagram that is difficult to understand. Each process is numbered with an integer, generally starting from the upper left-hand corner of the diagram and working toward the lower right-hand corner. The major data stores of the system (representing master files) and all external entities are included on Diagram 0. Figure below schematically illustrates both the context diagram and Diagram 0.
Because a data flow diagram is two-dimensional (rather than linear), you may start at any point and work forward or backward through the diagram. If you are unsure of what you would include at any point, take a different external entity, process, or data store, and then start drawing the flow from it. You may:
- Start with the data flow from an entity on the input side. Ask questions such as: “What happens to the data entering the system?” “Is it stored?” “Is it input for several processes?”
- Work backward from an output data flow. Examine the output fields on a document or screen. (This approach is easier if prototypes have been created.) For each field on the output, ask: “Where does it come from?” or “Is it calculated or stored on a file?” For example, when the output is a PAYCHECK, the EMPLOYEE NAME and ADDRESS would be located on an EMPLOYEE file, the HOURS WORKED would be on a TIME RECORD, and the GROSS PAY and DEDUCTIONS would be calculated. Each file and record would be connected to the process that produces the paycheck.
- Examine the data flow to or from a data store. Ask: “What processes put data into the store?” or “What processes use the data?” Note that a data store used in the system you are working on may be produced by a different system. Thus, from your vantage point, there may not be any data flow into the data store.
- Analyze a well-defined process. Look at what input data the process needs and what output it produces. Then connect the input and output to the appropriate data stores and entities.
- Take note of any fuzzy areas where you are unsure of what should be included or what input or output is required. Awareness of problem areas will help you formulate a list of questions for follow-up interviews with key users.
Creating Child Diagrams (More Detailed Levels)
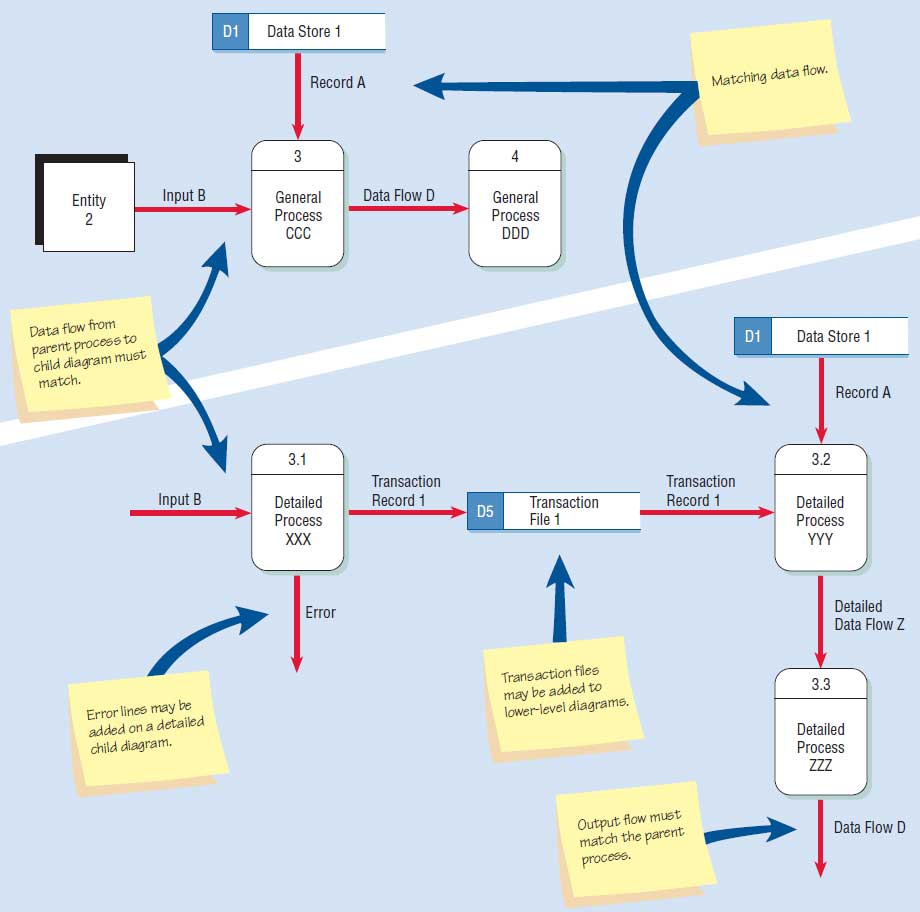
Each process on Diagram 0 may in turn be exploded to create a more detailed child diagram. The process on Diagram 0 that is exploded is called the parent process, and the diagram that results is called the child diagram. The primary rule for creating child diagrams, vertical balancing, dictates that a child diagram cannot produce output or receive input that the parent process does not also produce or receive. All data flow into or out of the parent process must be shown flowing into or out of the child diagram.
The child diagram is given the same number as its parent process in Diagram 0. For example, process 3 would explode to Diagram 3. The processes on the child diagram are numbered using the parent process number, a decimal point, and a unique number for each child process. On Diagram 3, the processes would be numbered 3.1, 3.2, 3.3, and so on. This convention allows the analyst to trace a series of processes through many levels of explosion. If Diagram 0 depicts processes 1, 2, and 3, the child diagrams 1, 2, and 3 are all on the same level.
Entities are usually not shown on the child diagrams below Diagram 0. Data flow that matches the parent flow is called an interface data flow and is shown as an arrow from or into a blank area of the child diagram. If the parent process has data flow connecting to a data store, the child diagram may include the data store as well. In addition, this lower-level diagram may contain data stores not shown on the parent process. For example, a file containing a table of information, such as a tax table, or a file linking two processes on the child diagram may be included. Minor data flow, such as an error line, may be included on a child diagram but not on the parent.
Processes may or may not be exploded, depending on their level of complexity. When a process is not exploded, it is said to be functionally primitive and is called a primitive process. Logic is written to describe these processes and is discussed in detail in Chapter 9. Figure below illustrates detailed levels in a child data flow diagram.