
Data dictionary entries may be created after the data flow diagram has been completed, or they may be constructed as the data flow diagram is being developed. The use of algebraic notation and structural records allows the analyst to develop the data dictionary and the data flow diagrams using a top-down approach. For instance, the analyst may create a Diagram 0 data flow after the first few interviews and, at the same time, make the preliminary data dictionary entries. Typically, these entries consist of the data flow names found on the data flow diagram and their corresponding data structures.
After conducting several additional interviews with users to learn the details of the system and the ways they interact with it, the analyst will expand the data flow diagram and create the child diagrams. The data dictionary is then modified to include the new structural records and elements gleaned from further interviews, observation, and document analysis.
Each level of a data flow diagram should use data appropriate for the level. Diagram 0 should include only forms, screens, reports, and records. As child diagrams are created, the data flow into and out of the processes becomes more and more detailed, including structural records and elements.
Figure below illustrates a portion of two data flow diagram levels and corresponding data dictionary entries for producing an employee paycheck. Process 5, found on Diagram 0, is an overview of the production of an EMPLOYEE PAYCHECK. The corresponding data dictionary entry for EMPLOYEE RECORD shows the EMPLOYEE NUMBER and four structural records, the view of the data obtained early in the analysis. Similarly, TIMEFILE RECORD and the EMPLOYEE PAYCHECK are also defined as a series of structures.
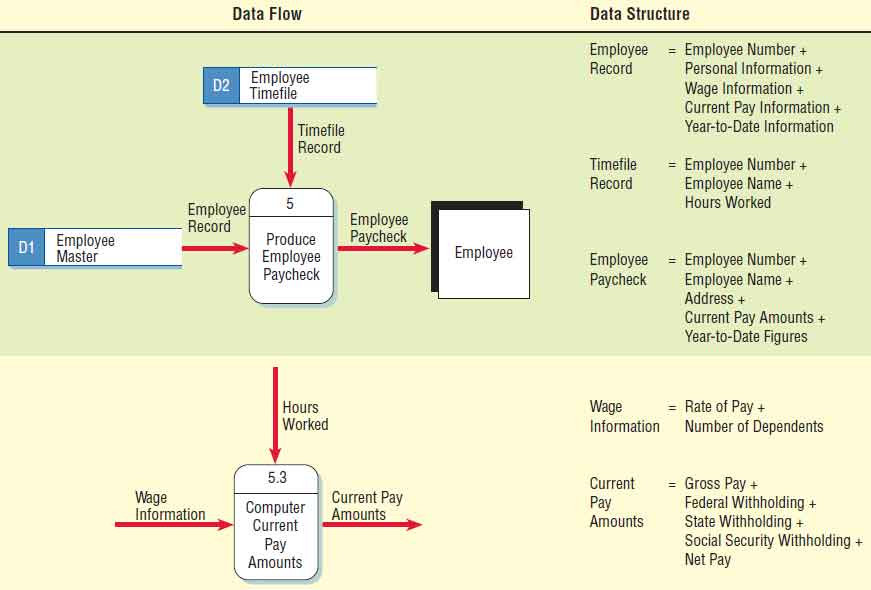
It is important that the data flow names on the child data flow diagram are contained as elements or structural records in the data flow on the parent process. Returning to the example, WAGE INFORMATION (input into process 5.3, COMPUTE CURRENT PAYAMOUNTS) is a structural record contained in the EMPLOYEE RECORD (input to process 5). Similarly, GROSS PAY(output from process 5.3.4, a lower-level process not shown in the figure) is contained in the structural record CURRENT PAYAMOUNTS (output from the parent process 5.3, COMPUTE CURRENT PAYAMOUNTS).
Analyzing Input and Output
An important step in creating the data dictionary is to identify and categorize system input and output data flow. Input and output analysis forms contain the following commonly included fields:
- A descriptive name for the input or output. If the data flow is on a logical diagram, the name should identify what the data are (for example, CUSTOMER INFORMATION). If the analyst is working on the physical design or if the user has explicitly stated the nature of the input or output, however, the name should include that information regarding the format. Examples are CUSTOMER BILLING STATEMENT and CUSTOMER DETAILS INQUIRY.
- The user contact responsible for further details clarification, design feedback, and final approval.
- Whether the data is input or output.
- The format of the data flow. In the logical design stage, the format may be undetermined.
- Elements indicating the sequence of the data on a report or screen (perhaps in columns).
- A list of elements, including their names, lengths, and whether they are base or derived, and their editing criteria.
Once the form has been completed, each element should be analyzed to determine whether the element repeats, whether it is optional, or whether it is mutually exclusive of another element. Elements that fall into a group or that regularly combine with several other elements in many structures should be placed together in a structural record.
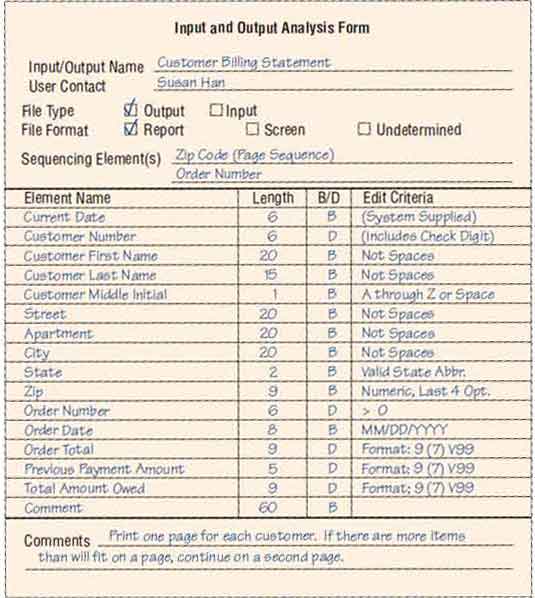
These considerations can be seen in the completed Input and Output Analysis Form for World’s Trend Catalog Division (see figure below). In this example of a CUSTOMER BILLING STATEMENT, the CUSTOMER FIRST NAME, CUSTOMER LAST NAME, and CUSTOMER MIDDLE INITIAL should be grouped together in a structural record.
Developing Data Stores
Another activity in creating the data dictionary is developing data stores. Up to now, we have determined what data needs to flow from one process to another. This information is described in data structures. The information, however, may be stored in numerous places, and in each place the data store may be different. Whereas data flows represent data in motion, data stores represent data at rest.
For example, when an order arrives at World’s Trend (see figure below), it contains mostly temporary information, that is, the information needed to fill that particular order, but some information might be stored permanently. Examples of the latter include information about customers (so catalogs can be sent to them) and information about items (because these items will appear on many other customers’ orders).
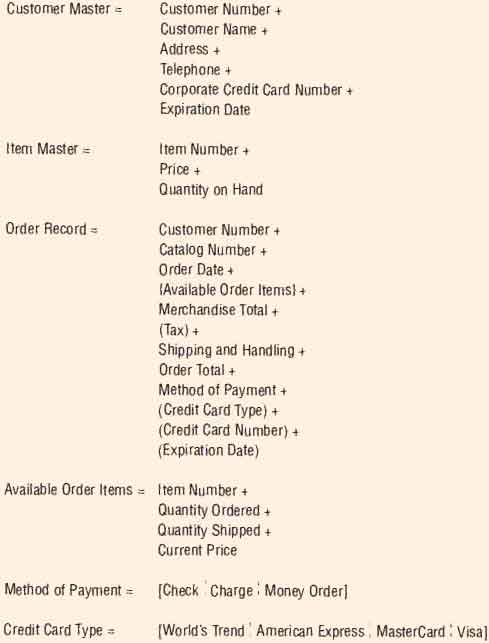
Data stores contain information of a permanent or semipermanent (temporary) nature. An ITEM NUMBER, DESCRIPTION, and ITEM COST are examples of information that is relatively permanent. So is the TAX RATE. When the ITEM COST is multiplied by the TAX RATE, however, the TAX CHARGED is calculated (or derived). Derived values do not have to be stored in a data store.
When data stores are created for only one report or screen, we refer to them as “user views,” because they represent the way that the user wants to see the information.