

Introduction
Gradient Descent is one of the most fundamental and widely-used optimization algorithms in machine learning and deep learning. It is the backbone of many algorithms used in supervised learning. Understanding Gradient Descent is crucial for anyone aiming to delve deeper into machine learning, as it provides insights into how models learn from data. This tutorial will guide you through implementing Gradient Descent from scratch in Python, ensuring you understand each step of the process.
Prerequisites
Before we start, it is essential to have a solid understanding of the following concepts:
- Basic Python programming
- Basic linear algebra (vectors and matrices)
- Calculus (partial derivatives)
- Basic understanding of machine learning models (especially linear regression)
1. Understanding Gradient Descent
What is Gradient Descent?
Gradient Descent is an optimization algorithm used to minimize the cost function in machine learning models. The cost function, also known as the loss function, measures the difference between the predicted values and the actual values. Gradient Descent iteratively adjusts the model parameters to minimize this cost function.
Types of Gradient Descent
There are three main types of Gradient Descent:
- Batch Gradient Descent: Uses the entire dataset to compute the gradient at each step.
- Stochastic Gradient Descent (SGD): Uses one data point at a time to compute the gradient.
- Mini-Batch Gradient Descent: Uses a small subset of the dataset to compute the gradient at each step.
The Mathematics Behind Gradient Descent
The core idea of Gradient Descent is to use the gradient (the vector of partial derivatives) of the cost function to adjust the parameters in the opposite direction of the gradient. This is because the gradient points in the direction of the steepest increase in the cost function, so moving in the opposite direction decreases the cost.
The update rule for the parameters (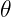 ) in Gradient Descent is:
) in Gradient Descent is:

Where:
 are the model parameters.
are the model parameters. is the learning rate, a small positive number that controls the step size.
is the learning rate, a small positive number that controls the step size. is the cost function.
is the cost function. is the gradient of the cost function with respect to (\theta).
is the gradient of the cost function with respect to (\theta).
 is the learning rate, a small positive number that controls the step size.
is the learning rate, a small positive number that controls the step size. is the cost function.
is the cost function. is the gradient of the cost function with respect to (\theta).
is the gradient of the cost function with respect to (\theta).2. Implementing Gradient Descent in Python
Setting Up the Environment
First, let’s set up our Python environment. Ensure you have Python installed, along with essential libraries like NumPy and Matplotlib. You can install them using pip if you haven’t already:
pip install numpy matplotlibCode language: Bash (bash)Dataset Preparation
For this tutorial, we’ll use a simple synthetic dataset for linear regression. Let’s create a dataset with a single feature and a target variable.
import numpy as np
import matplotlib.pyplot as plt
# Seed for reproducibility
np.random.seed(42)
# Generate synthetic data
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# Plot the data
plt.scatter(X, y)
plt.xlabel('Feature')
plt.ylabel('Target')
plt.title('Synthetic Data')
plt.show()Code language: Python (python)Linear Regression and Cost Function
Next, we define our linear regression model and the cost function. The model can be represented as:

The cost function for linear regression is the Mean Squared Error (MSE):

Where:
 is the number of training examples.
is the number of training examples. is the predicted value for the
is the predicted value for the  -th training example.
-th training example.- is the actual value for the -th training example.
 is the number of training examples.
is the number of training examples. is the predicted value for the
is the predicted value for the 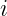 -th training example.
-th training example. is the actual value for the
is the actual value for the Let’s implement these in Python:
def predict(X, theta):
return X.dot(theta)
def compute_cost(X, y, theta):
m = len(y)
predictions = predict(X, theta)
cost = (1 / (2 * m)) * np.sum((predictions - y) ** 2)
return costCode language: Python (python)Implementing Batch Gradient Descent
Now, we’ll implement Batch Gradient Descent. This involves updating the parameters using the entire dataset at each step.
def batch_gradient_descent(X, y, theta, learning_rate, iterations):
m = len(y)
cost_history = np.zeros(iterations)
for i in range(iterations):
gradients = (1 / m) * X.T.dot(predict(X, theta) - y)
theta = theta - learning_rate * gradients
cost_history[i] = compute_cost(X, y, theta)
return theta, cost_history
# Prepare the data (add a column of ones for the bias term)
X_b = np.c_[np.ones((100, 1)), X]
theta = np.random.randn(2, 1)
learning_rate = 0.1
iterations = 1000
theta_final, cost_history = batch_gradient_descent(X_b, y, theta, learning_rate, iterations)
print("Final parameters:", theta_final)
plt.plot(range(iterations), cost_history)
plt.xlabel('Iterations')
plt.ylabel('Cost')
plt.title('Cost Function History')
plt.show()Code language: Python (python)Implementing Stochastic Gradient Descent
Stochastic Gradient Descent (SGD) updates the parameters using one data point at a time. This can lead to faster convergence on large datasets, though it can be more noisy.
def stochastic_gradient_descent(X, y, theta, learning_rate, iterations):
m = len(y)
cost_history = np.zeros(iterations)
for i in range(iterations):
for j in range(m):
random_index = np.random.randint(m)
xi = X[random_index:random_index+1]
yi = y[random_index:random_index+1]
gradients = 2 * xi.T.dot(predict(xi, theta) - yi)
theta = theta - learning_rate * gradients
cost_history[i] = compute_cost(X, y, theta)
return theta, cost_history
theta = np.random.randn(2, 1)
learning_rate = 0.01
iterations = 50
theta_final, cost_history = stochastic_gradient_descent(X_b, y, theta, learning_rate, iterations)
print("Final parameters:", theta_final)
plt.plot(range(iterations), cost_history)
plt.xlabel('Iterations')
plt.ylabel('Cost')
plt.title('Cost Function History')
plt.show()Code language: Python (python)Implementing Mini-Batch Gradient Descent
Mini-Batch Gradient Descent is a compromise between Batch Gradient Descent and SGD. It uses a small subset (batch) of the dataset at each step to compute the gradient.
def mini_batch_gradient_descent(X, y, theta, learning_rate, iterations, batch_size):
m = len(y)
cost_history = np.zeros(iterations)
for i in range(iterations):
shuffled_indices = np.random.permutation(m)
X_shuffled = X[shuffled_indices]
y_shuffled = y[shuffled_indices]
for j in range(0, m, batch_size):
xi = X_shuffled[j:j+batch_size]
yi = y_shuffled[j:j+batch_size]
gradients = (1 / batch_size) * xi.T.dot(predict(xi, theta) - yi)
theta = theta - learning_rate * gradients
cost_history[i] = compute_cost(X, y, theta)
return theta, cost_history
theta = np.random.randn(2, 1)
learning_rate = 0.1
iterations = 200
batch_size = 20
theta_final, cost_history = mini_batch_gradient_descent(X_b, y, theta, learning_rate, iterations, batch_size)
print("Final parameters:", theta_final)
plt.plot(range(iterations), cost_history)
plt.xlabel('Iterations')
plt.ylabel('Cost')
plt.title('Cost Function History')
plt.show()Code language: Python (python)3. Advanced Topics
Learning Rate Schedules
A static learning rate may not always be optimal. A learning rate schedule adjusts the learning rate over time to improve convergence.
def learning_rate_schedule(t, t0=5, t1=50):
return t0 / (t + t1)
def sgd_with_schedule(X, y, theta, iterations):
m = len(y)
cost_history = np.zeros(iterations)
for epoch in range(iterations):
for i in range(m
):
random_index = np.random.randint(m)
xi = X[random_index:random_index+1]
yi = y[random_index:random_index+1]
gradients = 2 * xi.T.dot(predict(xi, theta) - yi)
learning_rate = learning_rate_schedule(epoch * m + i)
theta = theta - learning_rate * gradients
cost_history[epoch] = compute_cost(X, y, theta)
return theta, cost_history
theta = np.random.randn(2, 1)
iterations = 50
theta_final, cost_history = sgd_with_schedule(X_b, y, theta, iterations)
print("Final parameters:", theta_final)
plt.plot(range(iterations), cost_history)
plt.xlabel('Iterations')
plt.ylabel('Cost')
plt.title('Cost Function History with Learning Rate Schedule')
plt.show()Code language: Python (python)Gradient Descent with Momentum
Momentum helps accelerate Gradient Descent in the relevant direction and dampens oscillations.
def gradient_descent_with_momentum(X, y, theta, learning_rate, iterations, beta=0.9):
m = len(y)
cost_history = np.zeros(iterations)
v = np.zeros(theta.shape)
for i in range(iterations):
gradients = (1 / m) * X.T.dot(predict(X, theta) - y)
v = beta * v + (1 - beta) * gradients
theta = theta - learning_rate * v
cost_history[i] = compute_cost(X, y, theta)
return theta, cost_history
theta = np.random.randn(2, 1)
learning_rate = 0.1
iterations = 1000
theta_final, cost_history = gradient_descent_with_momentum(X_b, y, theta, learning_rate, iterations)
print("Final parameters:", theta_final)
plt.plot(range(iterations), cost_history)
plt.xlabel('Iterations')
plt.ylabel('Cost')
plt.title('Cost Function History with Momentum')
plt.show()Code language: Python (python)Adaptive Gradient Descent Methods (AdaGrad, RMSProp, Adam)
Adaptive methods adjust the learning rate based on past gradients.
AdaGrad:
def adagrad(X, y, theta, learning_rate, iterations, epsilon=1e-8):
m = len(y)
cost_history = np.zeros(iterations)
G = np.zeros(theta.shape)
for i in range(iterations):
gradients = (1 / m) * X.T.dot(predict(X, theta) - y)
G += gradients ** 2
adjusted_gradients = gradients / (np.sqrt(G) + epsilon)
theta = theta - learning_rate * adjusted_gradients
cost_history[i] = compute_cost(X, y, theta)
return theta, cost_history
theta = np.random.randn(2, 1)
learning_rate = 0.1
iterations = 1000
theta_final, cost_history = adagrad(X_b, y, theta, learning_rate, iterations)
print("Final parameters:", theta_final)
plt.plot(range(iterations), cost_history)
plt.xlabel('Iterations')
plt.ylabel('Cost')
plt.title('Cost Function History with AdaGrad')
plt.show()Code language: Python (python)RMSProp:
def rmsprop(X, y, theta, learning_rate, iterations, beta=0.9, epsilon=1e-8):
m = len(y)
cost_history = np.zeros(iterations)
E = np.zeros(theta.shape)
for i in range(iterations):
gradients = (1 / m) * X.T.dot(predict(X, theta) - y)
E = beta * E + (1 - beta) * gradients ** 2
adjusted_gradients = gradients / (np.sqrt(E) + epsilon)
theta = theta - learning_rate * adjusted_gradients
cost_history[i] = compute_cost(X, y, theta)
return theta, cost_history
theta = np.random.randn(2, 1)
learning_rate = 0.01
iterations = 1000
theta_final, cost_history = rmsprop(X_b, y, theta, learning_rate, iterations)
print("Final parameters:", theta_final)
plt.plot(range(iterations), cost_history)
plt.xlabel('Iterations')
plt.ylabel('Cost')
plt.title('Cost Function History with RMSProp')
plt.show()Code language: Python (python)Adam:
def adam(X, y, theta, learning_rate, iterations, beta1=0.9, beta2=0.999, epsilon=1e-8):
m = len(y)
cost_history = np.zeros(iterations)
v = np.zeros(theta.shape)
s = np.zeros(theta.shape)
for i in range(iterations):
gradients = (1 / m) * X.T.dot(predict(X, theta) - y)
v = beta1 * v + (1 - beta1) * gradients
s = beta2 * s + (1 - beta2) * gradients ** 2
v_corrected = v / (1 - beta1 ** (i + 1))
s_corrected = s / (1 - beta2 ** (i + 1))
theta = theta - learning_rate * v_corrected / (np.sqrt(s_corrected) + epsilon)
cost_history[i] = compute_cost(X, y, theta)
return theta, cost_history
theta = np.random.randn(2, 1)
learning_rate = 0.01
iterations = 1000
theta_final, cost_history = adam(X_b, y, theta, learning_rate, iterations)
print("Final parameters:", theta_final)
plt.plot(range(iterations), cost_history)
plt.xlabel('Iterations')
plt.ylabel('Cost')
plt.title('Cost Function History with Adam')
plt.show()Code language: Python (python)4. Testing and Evaluation
Visualizing the Gradient Descent Process
Visualizing the convergence of the cost function helps understand how the algorithm progresses.
plt.plot(range(iterations), cost_history)
plt.xlabel('Iterations')
plt.ylabel('Cost')
plt.title('Cost Function History')
plt.show()Code language: Python (python)Evaluating the Model Performance
Finally, let’s evaluate our model’s performance by calculating the Mean Absolute Error (MAE) and R-squared (R²) score.
from sklearn.metrics import mean_absolute_error, r2_score
# Predictions
y_pred = predict(X_b, theta_final)
# Evaluation metrics
mae = mean_absolute_error(y, y_pred)
r2 = r2_score(y, y_pred)
print(f"Mean Absolute Error: {mae}")
print(f"R-squared: {r2}")Code language: Python (python)5. Conclusion and Further Reading
In this tutorial, we covered:
- The basics of Gradient Descent and its variants (Batch, Stochastic, Mini-Batch)
- Implementing these variants from scratch in Python
- Advanced optimization techniques like Momentum, AdaGrad, RMSProp, and Adam
- Visualizing and evaluating the Gradient Descent process
Gradient Descent is a cornerstone of many machine learning algorithms, and mastering its implementation provides a solid foundation for further exploration in the field.
For further reading, consider exploring:
- “Deep Learning” by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
- “Pattern Recognition and Machine Learning” by Christopher M. Bishop
- Online courses like Andrew Ng’s Machine Learning on Coursera or the Deep Learning Specialization
By understanding and implementing Gradient Descent, you now have a powerful tool at your disposal to optimize various machine learning models.